Overview¶
Why Unstable Baselines?¶
UnstableBaselines is an Async-, Online-, Multi-Agent RL library focused on simplicity and hackability. It is designed for fast research iteration on reasoning models for TextArena games with a LoRA-first workflow. We do not harness complex GPU-scaling strategies and, therefore, offer lightweight and easy to use RL for small models. We believe reinforcement learning should not only belong to large research groups with massive compute resources. Unstable Baselines is, therefore, designed to run learning algorithms on a single GPU, making reinforcement learning accessible for (almost) everyone.
Why Reinforcement Learning for Text-Based Games?¶
Text-based games provide an ideal setting for developing reasoning-capable language models through interaction rather than imitation. Self-play introduces an emergent curriculum: as agents improve, they automatically encounter stronger opponents and more complex situations, ensuring a continuously evolving training signal. This interplay of interaction, adaptation, and self-generated challenge makes RL in text-based games a powerful approach to building adaptive, self-improving language agents capable of grounded reasoning and communication.
Architecture¶
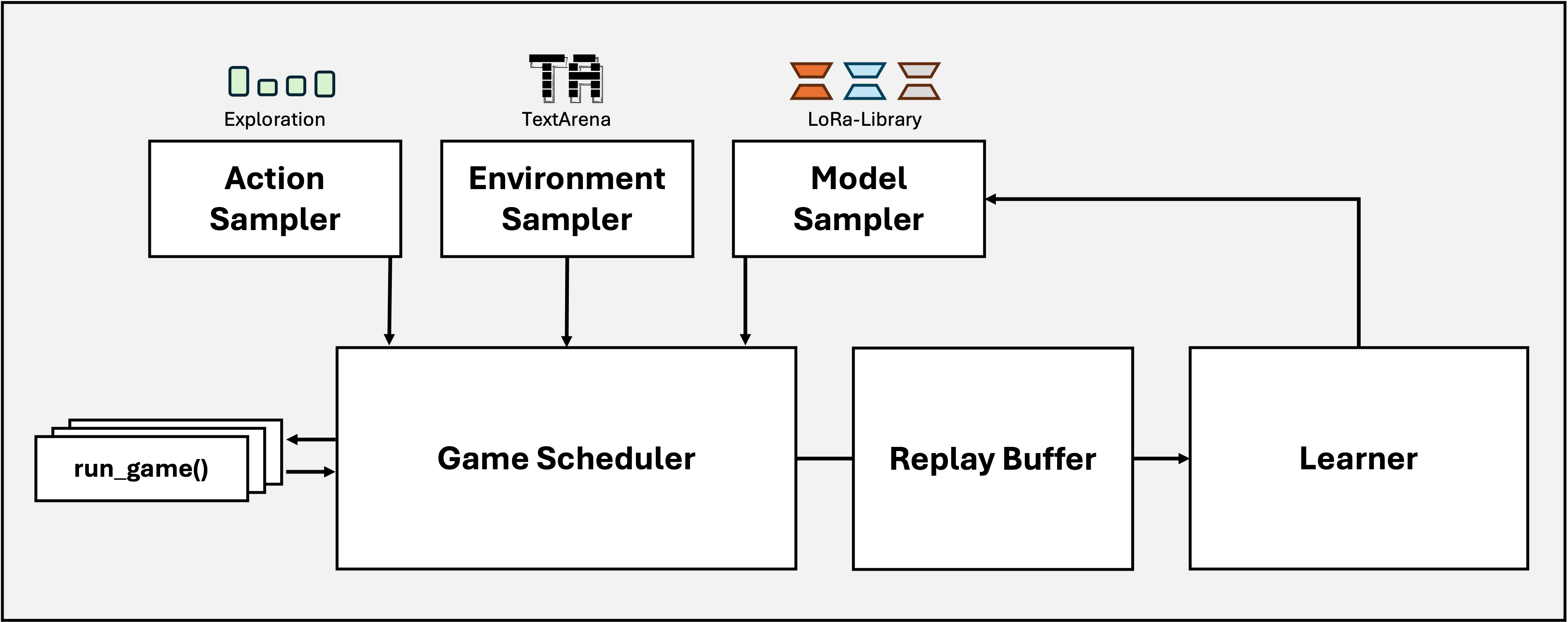
Action Sampler. The action sampler queries the large language model. Default is that a single response is sampled. However, we have also implemented MajorityVoting and you are free to experiment with different action selection strategies.
Environment Sampler. The environment sampler keeps a list of environments and chooses the one for the next game. Default is that a random environment is selected. However, the component offers possibilities for research on curriculum learning.
Model Sampler. By default, we do mirror self-play. However, the model sampler keeps a list of all checkpoints and fixed endpoints to external large language models to facilitate research on opponent selection.
Game Scheduler. The game scheduler implements the logic to start the next games asynchronously and collect the results. It queries the environment and model sampler for the next game and pushes the results to the replay buffer.
Learner. The learner does the actual training of the large language model. It fetches data from the replay buffer, computes the loss, updates the model, and registers the checkpoint. You can scale the learner to multiple GPUs utilizing DeepSpeed. We further speed things up with FlashAttention and mixed-precision training.
Replay Buffer. The replay buffer stores the game interaction data. Default is that steps are stored. However, we have also provide an episode buffer that returns full episodes for training. In the future, we envision different prioritization strategies to sample important experiences more frequently.