Replay Buffers¶
We provide two replay buffers for multi-agent game collection: StepBuffer stores and samples individual steps across episodes while the EpisodeBuffer stores and samples entire episodes.
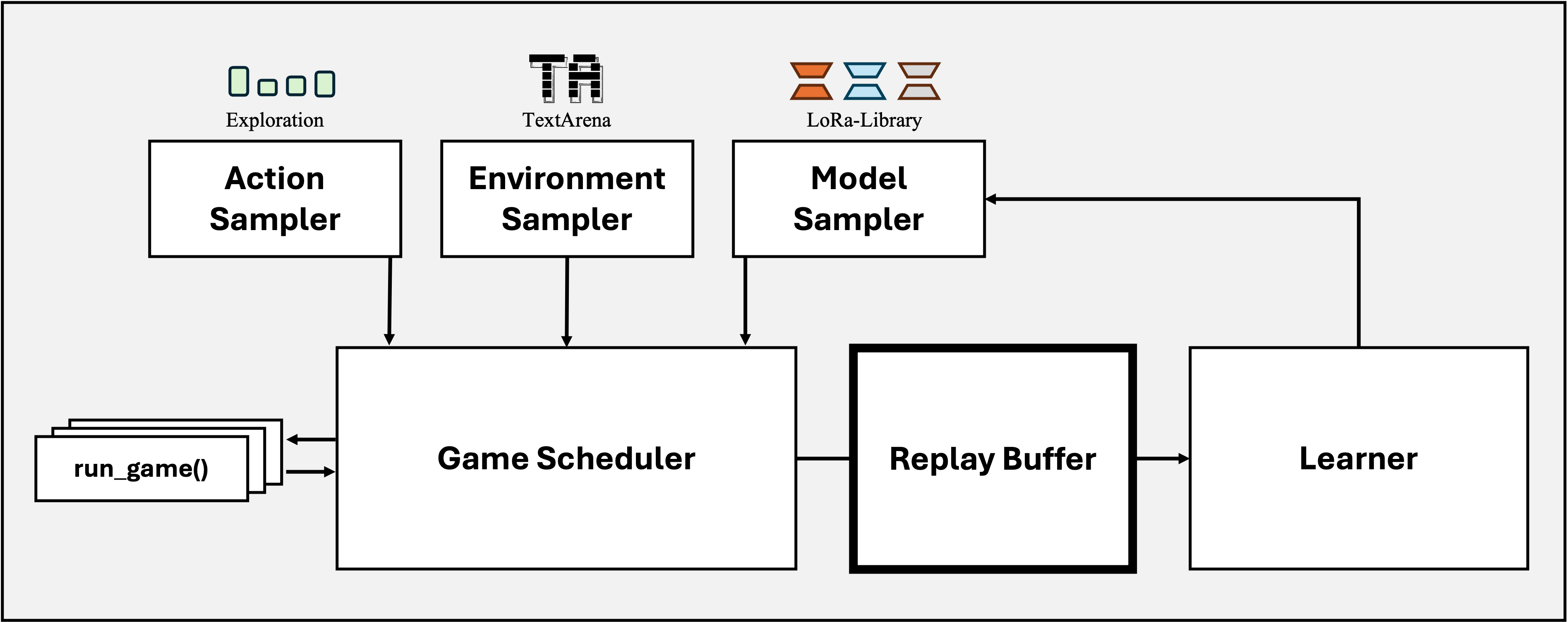
Both buffers support three kinds of reward transformations:
Final reward transformation: Applied once per trajectory and passed into step-level computations.
Step reward transformation Applied per step, typically using the final/episode reward.
Sampling reward transformation Applied at sampling time to the batch being returned.
API Reference¶
- class BaseBuffer(max_buffer_size, tracker, final_reward_transformation, step_reward_transformation, sampling_reward_transformation, buffer_strategy: str = 'random')¶
Abstract base with a minimal interface common to both buffers.
- Parameters:
max_buffer_size (int) – Maximum number of steps the buffer can hold in total.
tracker (unstable.collection.trackers.BaseTracker) – Tracker for logging.
final_reward_transformation (Optional[ComposeFinalRewardTransforms]) – Transformation applied once per trajectory to produce an episode-level reward.
step_reward_transformation (Optional[ComposeStepRewardTransforms]) – Per-step transformation producing the step reward.
sampling_reward_transformation (Optional[ComposeSamplingRewardTransforms]) – Transformation applied when sampling a batch.
buffer_strategy (str) – Buffer when full. Currently
"random"downsampling is implemented.
Expected methods
- add_player_trajectory(player_traj, env_id)
Add one complete trajectory to the buffer.
- get_batch(batch_size)
Sample and remove a batch from the buffer.
- stop()
Signal collection to stop.
- size() int
Current number of stored steps.
- continue_collection() bool
Whether the buffer is still accepting data.
- clear()
Remove all stored data.
StepBuffer¶
- class unstable.collection.buffers.StepBuffer(max_buffer_size, tracker, final_reward_transformation, step_reward_transformation, sampling_reward_transformation, buffer_strategy: str = 'random')
Stores steps from incoming trajectories in a single flat list and samples individual steps.
- Parameters:
max_buffer_size (int) – Upper bound on number of stored steps. When exceeded, the buffer downsamples.
tracker (ray.actor.ActorHandle) – Tracker for logging.
final_reward_transformation (Optional[ComposeFinalRewardTransforms]) – Applied once per trajectory to produce a reward signal passed to per-step logic.
step_reward_transformation (Optional[ComposeStepRewardTransforms]) – Applied to each step (given the trajectory and index) to yield the stored step reward.
sampling_reward_transformation (Optional[ComposeSamplingRewardTransforms]) – Applied to the sampled batch of steps before returning it.
buffer_strategy (str) – Downsampling policy. Currently only
"random"is supported.
Methods
- add_player_trajectory(player_traj: PlayerTrajectory, env_id: str)¶
Add the trajectory to the buffer. For each step:
Compute the final reward transformation if provided; otherwise it uses the final reward of the trajectory.
Compute the step reward transformation if provided; otherwise it uses the final reward.
After insertion, if the number of stored steps exceeds the maximum buffer size, the buffer downsamples.
- Parameters:
player_traj (PlayerTrajectory) – The trajectory.
env_id (str) – Environment identifier.
- get_batch(batch_size: int) List[Step]¶
Sample without replacement a set of steps and remove them from the buffer.
- Parameters:
batch_size (int) – Number of steps to sample.
- stop()¶
Mark the buffer as closed to further collection. Does not clear data.
- size() int¶
Current number of stored steps.
- clear()¶
Remove all stored steps.
EpisodeBuffer¶
- class unstable.collection.buffers.EpisodeBuffer(max_buffer_size, tracker, final_reward_transformation, step_reward_transformation, sampling_reward_transformation, buffer_strategy: str = 'random')
Stores entire episodes and samples batches of full episodes.
- Parameters:
max_buffer_size (int) – Upper bound on number of stored steps. When exceeded, the buffer downsamples.
tracker (ray.actor.ActorHandle) – Tracker for logging.
final_reward_transformation (Optional[ComposeFinalRewardTransforms]) – Applied once per trajectory to produce a reward signal passed to per-step logic.
step_reward_transformation (Optional[ComposeStepRewardTransforms]) – Applied to each step (given the trajectory and index) to yield the stored step reward.
sampling_reward_transformation (Optional[ComposeSamplingRewardTransforms]) – Applied to the sampled batch of steps before returning it.
buffer_strategy (str) – Downsampling policy. Currently only
"random"is supported.
Methods
- add_player_trajectory(player_traj: PlayerTrajectory, env_id: str)¶
Add the trajectory to the buffer. For each step:
Compute the final reward transformation if provided; otherwise it uses the final reward of the trajectory.
Compute the step reward transformation if provided; otherwise it uses the final reward.
After insertion, if the number of stored steps exceeds the maximum buffer size, the buffer downsamples entire episodes.
- Parameters:
player_traj (PlayerTrajectory) – The source trajectory.
env_id (str) – Environment identifier.
- get_batch(batch_size: int) List[List[Step]]¶
Sample without replacement a set of episodes and remove them from the buffer.
- Parameters:
batch_size (int) – Number of episodes to sample.
- stop()¶
Mark the buffer as closed to further collection. Does not clear data.
- size() int¶
Current number of stored steps.
- clear()¶
Remove all stored episodes.