Environment Sampler¶
Environment samplers define how training and evaluation environments are selected during data collection and evaluation. They provide a flexible interface for sampling from one or more configured environment specifications, with optional stochasticity or adaptive scheduling. We currently provide a uniform random sampler implementation.
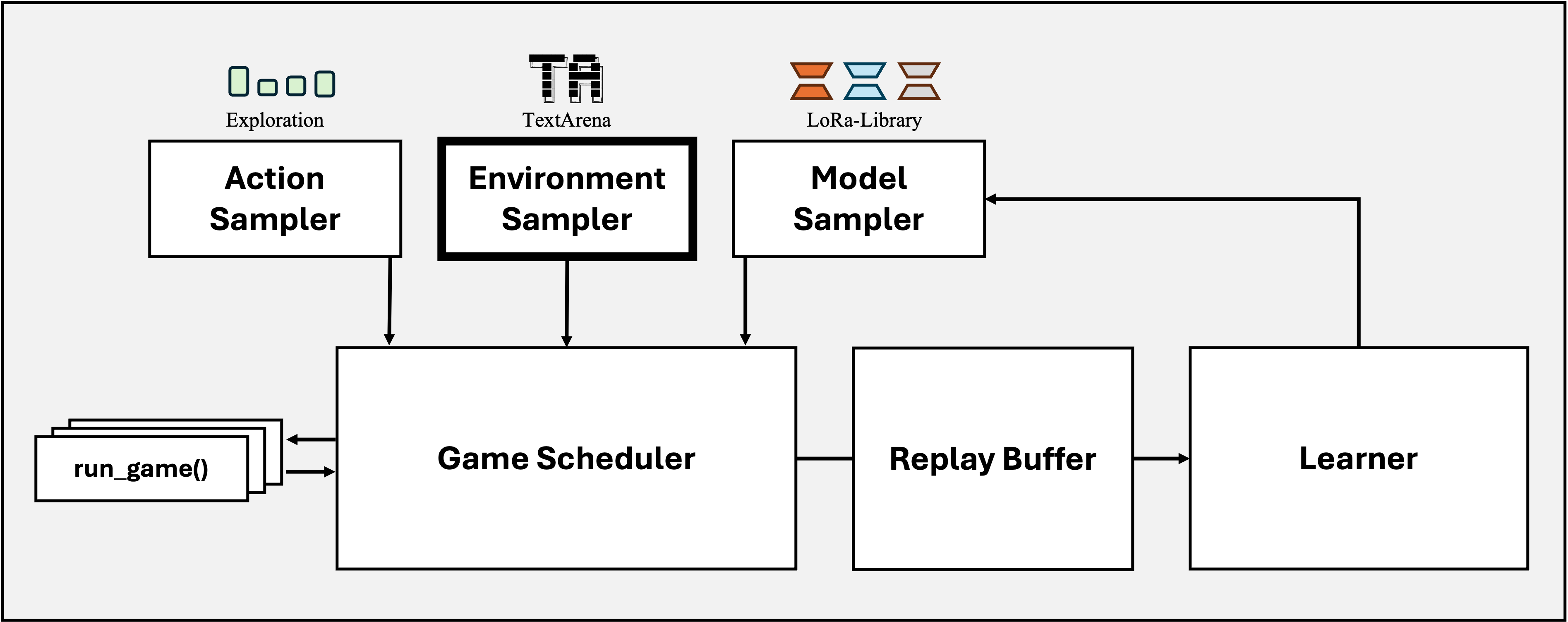
API Reference¶
- class BaseEnvSampler(train_env_specs, eval_env_specs=None, rng_seed=489)¶
Abstract base class for all environment samplers.
- Parameters:
train_env_specs (List[unstable.utils._types.TrainEnvSpec]) – List of environment specifications used for training.
eval_env_specs (Optional[List[unstable.utils._types.EvalEnvSpec]]) – Optional list of environment specifications used for evaluation.
rng_seed (Optional[int]) – Optional integer seed for reproducible random sampling.
Methods
- env_list() str¶
Return a comma-separated string listing the identifiers of all training environments.
Expected Methods
- sample(kind: str = 'train') TrainEnvSpec | EvalEnvSpec
Sample one environment specification according to the implemented strategy.
- Parameters:
kind (str) – Whether to sample from
"train"or"eval"environments.
- update(avg_actor_reward: float, avg_opponent_reward: float | None)
Update internal state based on observed training metrics.
- Parameters:
avg_actor_reward (float) – Average episodic reward achieved by the learning agent.
avg_opponent_reward (Optional[float]) – Optional average reward of the opponent (if applicable).
UniformRandomEnvSampler¶
- class unstable.collection.env_samplers.UniformRandomEnvSampler(train_env_specs, eval_env_specs=None, rng_seed=489)
Samples environments uniformly at random.
- Parameters:
train_env_specs (List[unstable.utils._types.TrainEnvSpec]) – List of environment specifications used for training.
eval_env_specs (Optional[List[unstable.utils._types.EvalEnvSpec]]) – Optional list of environment specifications used for evaluation.
rng_seed (Optional[int]) – Random seed for reproducibility.
Methods
- sample(kind: str = 'train') TrainEnvSpec | EvalEnvSpec¶
Sample a single environment specification uniformly at random.
- Parameters:
kind (str) – Sampling mode. Either
"train"or"eval".
- update(avg_actor_reward: float, avg_opponent_reward: float | None) None¶
This method is a no-op for the uniform random strategy, since sampling probabilities are fixed.
- Parameters:
avg_actor_reward (float) – Average episodic reward achieved by the learning agent.
avg_opponent_reward (Optional[float]) – Optional average reward of the opponent.
—